Właściwości elementów
Jeżeli pobierzesz jakikolwiek element ze strony, będziesz mógł w konsoli
wyświetlić jego właściwości i metody.
Najlepiej od razu odpal debuggera (F12) i zostaw konsolę widoczną, bo jeszcze nam się przyda.
Otwórz debuggera i kliknij w poniższy przycisk:
const btn = document.querySelector(".button");
console.log(btn);
console.dir(btn);
Obiekt taki ma bardzo dużo właściwości i metod. Część z nich przechowuje pozycję na stronie, typ elementu, jego rozmiary, inne są wykorzystywane dla zdarzeń itp.
Nie wszystkie będziesz non stop używał. Jeżeli trafi się taka konieczność, wiedz po prostu gdzie szukać tego co cię interesuje (wypisując pobrany element w konsoli za pomocą console.dir i badając odpowiednie właściwości).
Poniżej skupimy się na właściwościach i metodach, które są wykorzystywane najczęściej.
innerHTML
Właściwość innerHTML umożliwia odczyt i ustawianie html, jaki jest we wnętrzu danego elementu:
<button class="button">
<span>Kliknij mnie</span>
</button>
const btn = document.querySelector(".button");
console.log( btn.innerHTML ); //<span>Kliknij mnie</span>
btn.innerHTML = "<span>Nie klikaj mnie!</span>"
Otwórz debuggera i kliknij w poniższy przycisk:
Za pomocą innerHTML możemy oczywiście wstawiać całe kawałki dokumentu:
<div class="test-cnt">Tutaj zaraz coś wstawimy</div>
<button class="button" type="button">Wstaw element</button>
const btn = document.querySelector(".button");
btn.addEventListener("click", () => {
document.querySelector(".test-cnt").innerHTML = `
<div class="module">
<h2>Przykładowy tytuł</h2>
<p>To jest <strong>dynamicznie wstawiony html</strong></p>
<button class="button">klik</button>
</div>
`;
});
Wstawianie na stronę nowy HTML tak jak powyżej z pewnością jest bardzo wygodne i nie raz będziesz z tego korzystał. Warto się jednak tutaj na moment zatrzymać, ponieważ nie zawsze będzie to takie proste.
Na koniec mała uwaga. Starajcie się nie dodawać do innerHTML tekstu jak poniżej:
//ja dodałem słowo "lorem", ale to może być dowolny tekst lub html
document.body.innerHTML += 'lorem'
Taka operacja faktycznie doda nowy html do strony, ale też odepnie wszystkie zdarzenia dla elementów mieszczących się w danym elemencie (ale i w jego dzieciach). A tego raczej nie chcemy.
innerText i textContent
Właściwości innerText i textContent działają podobnie do powyższej innerHTML, z tym, że zwracają lub ustawiają sam tekst (bez znaczników HTML):
const btn = document.querySelector(".btn");
console.log(btn.innerHTML); //<span>Kliknij mnie</span>
console.log(btn.innerText); ///"Kliknij mnie"
console.log(btn.textContent); //"Kliknij mnie"
Obie właściwości pozwalają nam zwrócić i ustawić tekst elementu. Rozróżnia je to, że innerText działa na sparsowanym tekście, natomiast textContent na oryginalnym, jaki wpisaliśmy do pliku HTML.
Co to oznacza w praktyce? Gdy pobierasz tekst za pomocą innerText, zostanie on pobrany z zaaplikowanymi stylami. Fragmenty tekstu, które zostały ukryte za pomocą display:none i visibility:hidden nie zostaną zwrócone. Dodatkowo tekst taki nie będzie miał wcięć, a wszystkie napotkane znaczniki <br> i nowe linie w HTML zostaną zwrócone jako przejście do nowej linii.
Pobierając ten sam tekst za pomocą textContent zwróci nam tekst oryginalny, jaki napisaliśmy w pliku HTML z wszystkimi wcięciami i enterami które zrobiliśmy za pomocą tabulatora.
<div>
<span style="display: none">Ukryty</span>
<span>Obok mnie są dwa niewidoczne spany</span>
<span style="visibility: hidden">Niewidoczny</span>
</div>
<div>
Turlał goryl po górach kolorowe korale
Góral tarł na tarze kartofle wytrwale
</div>
To samo tyczy się wstawiania tekstu do elementu. Ustawiając wieloliniowy tekst za pomocą textContent zostanie on po prostu wstawiony do elementu w oryginalnej postaci, natomiast ten sam tekst wstawiany za pomocą innerText automatycznie doda nam <br>
const text = `
Mała muszka spod Łopuszki
chciała mieć różowe nóżki
Różdżką nóżki czarowała
lecz wciąż nóżki czarne miała
`;
const div = document.querySelector("#addTextTest");
const btn1 = document.querySelector("#textContent");
btn1.addEventListener("click", () => {
div.textContent = text.trim();
});
const btn2 = document.querySelector("#innerText");
btn2.addEventListener("click", () => {
div.innerText = text.trim();
});
tagName
Właściwość tagName zwraca nam nazwę elementu np. h2, a, p itp.
const btn = document.querySelector(".button");
console.log(btn.tagName);
Do czego to może się przydać? Przykładowo można pobrać wiele elementów na raz, a następnie tylko dla określonych coś zmieniać:
const elements = document.querySelectorAll("body *");
for (const el of elements) {
if (el.tagName === "STRONG") {
el.style.border = "1px solid red";
}
}
Dla elementów pobranych ze strony HTML nazwy znaczników są zwracane dużymi literami. Dla strony - np. xhtml już nie zawsze będzie to regułą.
Praca z atrybutami
Do pracy z atrybutami danego elementu (np. src dla img) możemy skorzystać z poniższych metod:
| el.getAttribute(name) | pobiera wartość danego atrybutu lub zwraca null jeżeli takiego nie ma |
|---|---|
| el.setAttribute(name, value) | ustawia nową wartość atrybutu |
| el.hasAttribute(name) | zwraca true/false w zależności czy element ma atrybut o danej nazwie |
| el.removeAttribute(name) | usuwa atrybut o danej nazwie |
| el.toggleAttribute(name) | dodaje/usuwa dany atrybut |
<a href="http://google.pl"> Wyszukaj </a>
const link = document.querySelector("a");
const href = link.getAttribute("href"); //"http://google.pl"
const target = link.getAttribute("target"); //null
link.setAttribute("target", "_blank");
if (link.hasAttribute("target")) {
console.log(link.getAttribute("target")); //"_blank"
}
const btn = document.querySelector("button");
const input = document.querySelector("input");
btn.addEventListener("click", () => {
input.toggleAttribute("readonly");
if (input.hasAttribute("readonly")) {
btn.innerText = "edytuj";
} else {
btn.innerText = "zakończ";
}
})
dataset
Atrybuty możemy podzielić na standardowe dostępne dla danych znaczników (np. src, alt, title, class itp.), oraz nasze własne. Te drugie powinny zaczynać się od słowa data- np. data-text, data-direction.
Własne atrybuty możemy obsługiwać za pomocą powyższych metod, ale możemy dla nich skorzystać z właściwości dataset. Jest to obiekt, którego kolejne właściwości są budowane na bazie niestandardowych atrybutów:
<div class="module"
data-type="important"
data-position="top"
data-my-custom-data="Przykładowy tekst"
> ... </div>
const tooltip = document.querySelector(".module");
console.log(tooltip.dataset.type); //"important"
console.log(tooltip.dataset.position); //"top"
console.log(tooltip.dataset.myCustomData); //"Przykładowy tekst"
Przy podawaniu nazwy danego atrybutu pomijamy początek data-, a myślniki w nazwie zamieniamy na zapis camelCase.
tooltip.dataset.myCustomData = "nowa wartość"; //utworzy w elemencie atrybut data-my-custom-data="nowa wartość"
tooltip.dataset.style = "primary"; //utworzy atrybut data-style="primary"
tooltip.dataset.moduleSize = "big" //utworzy atrybut data-module-size="big"
//to samo możemy uzyskać za pomocą getAttribute i setAttribute
tooltip.setAttribute("data-custom-data", "nowa wartość");
tooltip.setAttribute("data-style", "primary");
tooltip.setAttribute("data-module-size", "big");
Charakterystyczną rzeczą jest to, że atrybuty w znacznikach html zawsze są tekstem. Tak więc cokolwiek byśmy nie przetrzymywali w dataset, staje się to tekstem:
<div data-nr1="16" data-nr2="30"> ... </div>
console.log(typeof div.dataset.nr1, typeof div.dataset.nr2) //"string", "string"
console.log(div.dataset.nr1 + div.dataset.nr2); //"1630"
Niestandardowe atrybuty idealnie nadają się więc do przechowywania tekstów dynamicznie wstawianych na stronę, kawałków html, które zaraz wmontujemy w stronę, czy dodatkowych wartości służących do stylowania za pomocą atrybutów.
div.dataset.type = "error";
div[data-type="error"] {
color: red;
}
Przykładem (jednym z setek) mogą być tooltipy w popularnym frameworku Bootstrap. Dzięki dodatkowych atrybutom określana jest tutaj pozycja dymka.
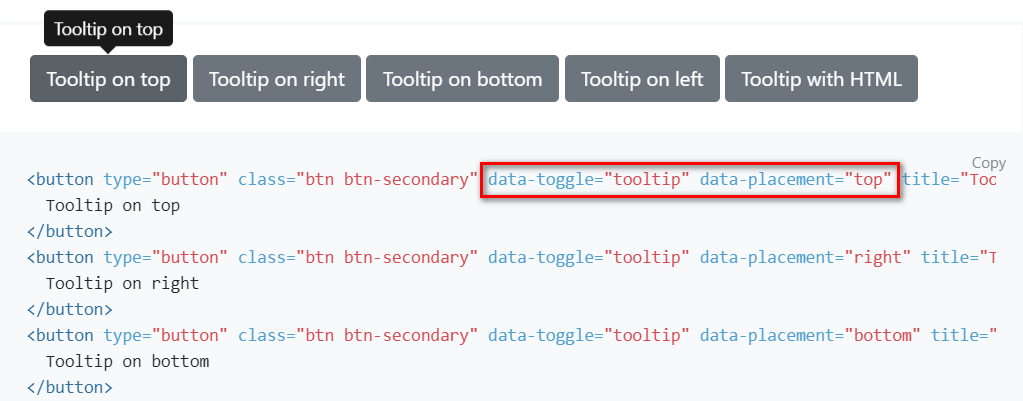
Przy liczbach także nie powinno być większych problemów, ponieważ łatwo możemy je konwertować:
console.log( +div.dataset.nr1 + +div.dataset.nr2 ); //46
Jeżeli z jakiś powodów chcielibyśmy przechowywać w atrybutach wartości tablic czy obiektów, musimy je skonwertować na format JSON:
//bez konwersji - źle
div.dataset.table = [1,2,3,4,5];
div.dataset.ob = {name : "Marcin"};
console.log(div.dataset.table); //"1,2,3,4,5"
console.log(div.dataset.ob); //"[object Object]"
//z konwersją - lepiej
div.dataset.table = JSON.stringify( [1,2,3,4,5] );
div.dataset.ob = JSON.stringify( {name : "Marcin"} );
console.log( JSON.parse(div.dataset.table) ); //["1,2,3,4,5"]
console.log( JSON.parse(div.dataset.ob) ); //{name : "Marcin"}
Tak skonwertowane obiekty nie mogą zawierać żadnych funkcji, dlatego dataset raczej nie nadaje się do przechowywania bardzo skomplikowanych danych, a tylko prostych tekstów lub wartości wykorzystanych do stylowania.
Atrybuty i właściwości
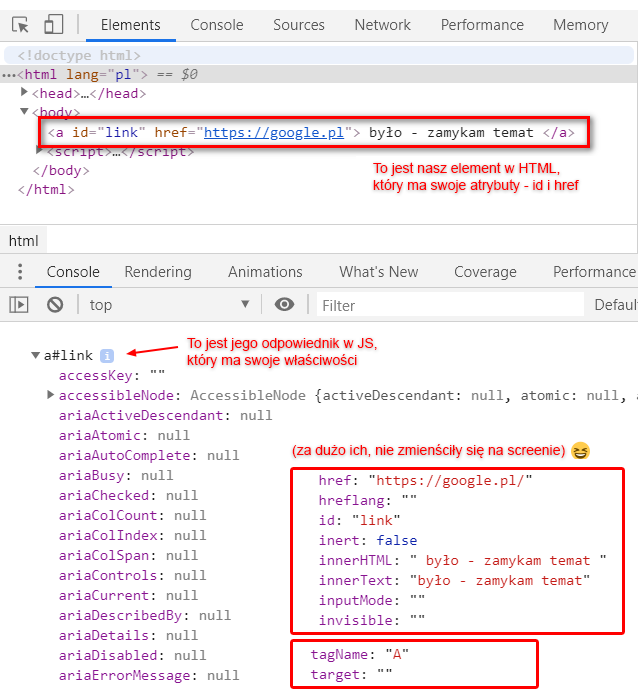
HTML to tak naprawdę kawałek tekstu, który napisaliśmy w dowolnym edytorze. Przeglądarka analizuje taki tekst, przetwarza, a następnie dla każdego elementu w HTML tworzy jego odzwierciedlenie w postaci odpowiedniego obiektu:
<a id="link" href="https://google.pl" target="_blank"> było - zamykam temat </a>
const link = document.querySelector("#link");
console.dir(link);
Obiekt taki automatycznie dostał wiele właściwości. Wśród nich są te, które odpowiadają atrybutom z html - np. id, href ale też takie które element danego typu potencjalnie może mieć. W powyższym przykładzie mamy link, więc ma on dla przykładu atrybut href. Nasz obiekt w JS także będzie miał taką właściwość.
<img src="obrazek.jpg" alt="obrazek" title="Fajny obrazek">
const img = document.querySelector("img");
img.src //"obrazek.jpg"
img.alt //"obrazek"
img.title //"Fajny obrazek"
Niektóre wartości są dodatkowo przeliczane:
<a id="link1" href="./kontakt.html"> kontakt </a>
<a id="link2" href="https://google.pl"> było. wygogluj sobie </a>
const link1 = document.querySelector("#link1");
console.log( link1.href ); //file:///C:/Users/kartofelek/Desktop/kontakt.html
const link2 = document.querySelector("#link1");
console.log( link2.href ); //https://google.pl
Atrybuty i właściwości są ze sobą scalone. Oznacza to, że przykładowo zmieniając atrybut href, zmienimy też właściwość href i vice wersa.
<a id="link" href="https://google.pl"> było - zamykam temat </a>
const a = document.querySelector("a");
a.href = "strona.html"
console.log(a.getAttribute("href")); //strona.html
const a = document.querySelector("a");
a.setAttribute("href", "strona.html"); //strona.html
console.log(a.getAttribute("href")); //file:///C:/Users/kartofelek/Desktop/test/strona.html
console.log(a.href);
Tu pojawia się też pewna ciekawostka.
Dla inputów w formularzach istnieją dwie właściwości - defaultValue i value.
Wchodząc na stronę z formularzem, część pól może być już domyślnie wypełniona. Mają one wtedy ustawiony atrybuty value np:
<input type="text" value="Piotrek">
Atrybut ten jest zmapowany z właściwością defaultValue, co oznacza, że jego wartość możemy odczytywać ale i zmienić na dwa sposoby:
input.setAttribute("value", "nowa-wartość");
input.defaultValue = "nowa-wartość"
Wartość value natomiast zawiera zawsze aktualną wartość pola. Po wejściu na stronę wartość ta będzie identyczna jak defaultValue. Gdy jednak użytkownik zacznie ręcznie edytować dane pole, właściwość value automatycznie zaktualizuje swoją wartość, natomiast atrybut (a co za tym idzie defaultValue) pozostanie bez zmian.
Dla nas oznacza to tyle, że jeżeli chcemy odczytać początkową wartość pola - użyjmy defaultValue. Natomiast jeżeli chcemy pobrać aktualną wartość pola - value. Podobna sytuacja będzie się dziać w przypadku checkboxów i radio gdzie mamy właściwości defaultChecked i checked.
Dla bardzo dociekliwych mechanizm ten opisany jest w dokumentacji.
Trening czyni mistrza
Jeżeli chcesz sobie potrenować zdobytą wiedzę, zadania znajdują się w repozytorium pod adresem: https://github.com/kartofelek007/zadania