AJAX
W poprzednim rozdziale rozmawialiśmy sobie o funkcjach asynchronicznych, czyli takich, których wykonanie zajmuje jakiś czas, ale równocześnie które nie blokują działania reszty kodu.
Nie są to jedyne miejsca, gdzie możemy spotkać się z asynchronicznością.
AJAX czyli Asynchronous JavaScript and XML to technika, wzorzec, który umożliwia nam dynamiczne ściąganie i wysyłanie danych bez potrzeby przeładowania całej strony.
W dzisiejszych czasach jest to w zasadzie norma na stronach. Gdy wchodzisz na Facebooka, przeglądasz sobie walla wczytując kolejne posty, ale równocześnie piszesz komentarz, obrażasz znajomych. Podobnie na Gmailu - mogę czytać maile, odpisywać, usuwać - a to wszystko będzie się dziać bez zbędnego przeładowania całej strony.
Zanim przejdziemy do praktyki, musimy sobie omówić kilka rzeczy, z którymi cała ta asynchroniczność jest związana.
Protokół HTTP
Komunikacja w Internecie bazuje na protokołach. Z pewnością o nich słyszałeś i bardzo często używałeś. Mamy więc dla przykładu smtp, imap, ftp, itp (1).
Ten związany ze stronami opiera się o protokół HTTP (przy czym już można trafić na protokół HTTP2, a już w planach jest HTTP3). Będą one usprawniały działanie HTTP.
A właściwie co mają usprawniać?
Gdy robimy zapytanie o jakiś zasób (np. wchodzimy na daną stronę, pobieramy jakąś grafikę, plik CSS itp.), przeglądarka wysyła w internet żądanie. Od razu włącz debuggera i przejdź na zakładkę Network. Następnie odśwież stronę by wczytać ponownie zasoby. Jak zauważysz, pierwszym zapytaniem (requestem), który wykona twoja przeglądarka będzie zapytanie o kod właśnie tej strony.
Twoja przeglądarka wysłała zapytanie o adres "/kurs/ajax/ajax.php". Wraz z tym zapytaniem dodatkowo wysyła kilka nagłówków informacyjnych. Można to porównać do wysyłania listu, gdzie na kopercie wypisujesz dane nadawcy.
Kliknij w debuggerze na pierwszy request i zbadaj jego postać. Zobaczysz tam sekcję Request headers.
Wśród tych nagłówków są informacje takie jak rodzaj przeglądarki, jakie typy danych ona obsługuje, jaki preferuje język, rodzaj cache, jakie akceptuje pakowanie danych itp.

Takie zapytanie leci w Internet, ale nie trafia ono bezpośrednio do serwera na którym znajduje się żądana strona. Każdy komputer w internecie ma swój numer IP. Jeżeli chcesz znaleźć swój, możesz skorzystać ze strony https://www.whatismyip.com/.
My wysłaliśmy zapytanie o adres "/kurs/ajax/ajax.php", a w internecie komputery istnieją pod postacią adresów IP. Zapytanie to trafia na serwer DNS, które mapuje dany "ludzki" adres na odpowiedni numer IP. Dzięki takiemu mapowaniu nasze zapytanie wędruje do odpowiedniego serwera w Internecie.
Po dotarciu do docelowego serwera, ten analizuje dane zapytanie, coś tam sobie dłubie, może pobiera dane z jakiś plików, bazy danych itp. Po wykonaniu odpowiednich czynności zwraca nam odpowiedź, która składa się z:
- Statusu odpowiedzi
- 0 lub więcej nagłówków (np. jakiego typu jest dana odpowiedź, jej długości, ważności itp.)
- Ciała odpowiedzi - body - (które nie zawsze występuje)
Nagłówki odpowiedzi (response headers) jak i ciało odpowiedzi możesz sobie przejrzeć w zakładce Network w tym samym miejscu co powyżej. Taka odpowiedź może wyglądać jak tak z poniższego screenu:
Gdy przeglądarka dostatnie taką odpowiedź, zaczyna czytać ciało odpowiedzi.
Dochodzi do momentu, gdzie np. za pomocą znacznika <link> dołączone są style do strony, czy np. w html użyta jest grafika . Przeglądarka wysyła kolejne żądanie (wraz z nagłówkami request headers), serwer je przetwarza i odsyła stosowną odpowiedź.
Ale co to. Autor w swoim HTML wrzucił film z Youtube. Przeglądarka natrafia na taki zapis i ponownie wykonuje żądanie. Natrafiając na kolejne zasoby w naszym kodzie, przeglądarka wysyła kolejne żądania. Coś jak przy grze w pingponga. Przeglądarka robi zagranie, serwer odpowiada...
W powyższym opisie kilka rzeczy ma dla nas szczególne znaczenie.
Pierwszą z nich jest status, czyli oznaczenie, czy dane połączenie się zakończyło sukcesem lub np. niepowodzeniem, bo dany adres nie istnieje.
Najczęściej spotykane statusy odpowiedzi to:
| 200 | Wszystko ok, połączenie zakończyło się sukcesem, dostaliśmy dane |
|---|---|
| 301 | Strona została przeniesiona na inny adres |
| 404 | Nie ma takiej strony |
| 500 | Błąd serwera |
Resztę dostępnych statusów możesz zobaczyć na tej stronie.
Wśród nagłówków "response headers" warto zwrócić uwagę na kilka z nich.
Nagłówek content/type, określa typ MIME danych. Jest to rodzaj danego pliku czy dokumentu. Dla przykładu dokument HTML ma typ text/html, filmy mp4 mają typ video/mp4, a pliki dźwiękowe WAV mają audio/x-wav. Mime type nie jest jakąś specyficzną rzeczą dla protokołu HTTP. Każdy plik jaki używamy na naszych komputerach ma swój typ który określany jest właśnie przez MIME type.
Tu pojawia się mała ciekawostka. Jeżeli serwer wyśle nam dokument HTML (stronę, o którą prosiliśmy), ale jako typ ustawi text/plain, wtedy w naszej przeglądarce strona wyświetli się jako plik tekstowy. Podobnie z całą resztą zasobów - gdy serwer pomyli się i wyśle grafikę png jako image/jpg, w naszej przeglądarce możemy zobaczyć plik jpg, który ma przezroczyste tło (a przecież jpg nie mają przezroczystego tła). Można to porównać do sytuacji, gdy masz na dysku plik png, i ręcznie zmieniasz mu rozszerzenie na jpg. Zadziałać zadziała, przy czym nie jest to poprawne działanie.
Kolejną bardzo ważną właściwością każdego połączenia jest jego typ. Jeżeli wejdziesz do debuggera i zakładki Network, a następnie odświeżysz stronę, zobaczysz, że większość połączeń będzie typu GET. Dlatego, że pobieramy dane. Takich typów jest kilka:
| GET | Ten typ połączenia służy do pobieranie danych. Można wykorzystać go też do przekazywania (wysyłania) danych, które to stosujemy przy formularzach w kodzie HTML lub dość często do komunikacji między podstronami danego portalu. Dane te są dołączane do adresu strony. Tego typu przekazywania danych używa się do pracy na stosunkowo małej ilości danych, ponieważ liczba liter w adresie wynosi ok 2000, więc i dane nie mogą być bardzo długie. Z pewnością spotkałeś się z takim przesyłaniem danych. Wystarczy skorzystać z praktycznie każdej strony w Internecie by zobaczyć jak doklejane są dane do adresu strony (Facebook, GMail, Google Maps itp.) |
|---|---|
| POST | wykorzystywany do wysyłania danych. Ten typ danych jest dołączany do ciała requestu, a nie do adresu strony. Można go podejrzeć w zakładce Network na samym dole danego requestu, który wysłał dane. |
| PUT / PATCH | typ połączenia używany do edycji rekordu. Różnica między nimi jest taka, że przy PUT edytujemy cały rekord na raz, dlatego musimy podać wszystkie składowe danego rekordu. Niepodane dane zostaną zastąpione wartością null, lub zostaną usunięte. W przypadku PATCH edytujemy tylko pojedyncze dane, dlatego możemy podać np. tylko imię czy nazwisko. |
| PATCH | Podobny do PUT, z tym że wykorzystuje się do edycji pojedynczej właściwości obiektu w bazie danych - np. nazwiska użytkownika. Dzięki temu nie musisz wysyłać wszystkich danych edytowanego elementu. Porównaj to do edycji obiektu. Przy PUT ustawiasz pod zmienną nowy obiekt. Przy PATCH zmieniasz tylko wybrane właściwości. |
| DELETE | Określa typ połączenia służący do usuwania danych |
Połączenia typu GET i POST mogą być przez nas wykorzystywane przy tworzeniu formularzy w HTML.
Cała reszta połączeń (włącznie z GET i POST) wykorzystywana jest przy połączeniach asynchronicznych wykonywanych za pomocą Javascript.
Warto też obejrzeć poniższy film:
RESTful API
Wysyłając czy pobierając dane zawsze będziesz się łączył do jakiegoś miejsca (serwera). Stamtąd możesz pobierać czy wysyłać dane w dowolnym formacie. Chcesz ściągnąć plik tekstowy? Proszę bardzo. A może kawałek HTML? Też nie ma problemu. Zresztą na co dzień nie raz się z tym spotykamy - czy to przez wysyłanie zdjęcia znajomemu na Messengerze, czy pobieraniu jakiegoś pliku z internetu.
//pobieram plik za pomocą jquery
$.get("http://mojserwer.pl/file.txt").done(res => {
console.log(res);
});
Częstokroć dane na serwerze będą bardziej skomplikowane niż pojedynczy plik. Jednym połączeniem będziemy chcieli coś pobrać, innym edytować czy usunąć - np. książkę z bazy danych.
Żeby było to możliwe, powinieneś przygotować odpowiednie adresy na które będziesz się łączyć. Jeden adres do pobrania kolekcji książek, drugi do pobrania pojedynczej książki, jej edycji, usunięcia itp.
REST (Representational State Transfer) to konwencja, wzór, a w zasadzie cytując wikipedię styl architektury, która określa jak powinny takie adresy wyglądać.
Wyobraź sobie, że w celu pobierania danych będziemy łączyć się na serwer pod adresem: http://bohaterowie.pl.
Gdybyśmy budowali nasz serwer w oparciu o REST, odpowiednie adresy mogły by mieć postać:
| Metoda HTTP | Adres | Opis |
|---|---|---|
| GET | http://bohaterowie.pl | Pobranie całej listy bohaterów |
| POST | http://bohaterowie.pl | Wysłanie/dodanie nowego bohatera |
| GET | http://bohaterowie.pl/10 | Pobranie danych bohatera o id 10 |
| PUT / PATCH | http://bohaterowie.pl/10 | Aktualizacja/edycja bohatera o id 10 |
| DELETE | http://bohaterowie.pl/10 | Usunięcie bohatera o id 10 |
Teraz jeżeli dasz mi adres http://bohaterowie.pl, a ja będę wiedział, że masz tam postawione RESTApi to mogę założyć, że gdy chcę dodać nowego użytkownika, dane powinienem wysłać za pomocą połączenia typu POST na adres http://bohaterowie.pl. Ale już edytując jakiegoś użytkownika, pewnie wyślę dane za pomocą PUT na adres http://bohaterowie.pl/ID. Jedyna rzecz, która była by mi potrzebna to opis danych jakie ściągnę, ale też jakie będę musiał wysłać.
Gdy będziesz łączył się do dostępnych w necie API, zobaczysz, że wiele z nich wymaga dodatkowych parametrów (np. klucz, czy szukany tekst).
Bardzo fajny artykuł na ten temat znajduje się pod adresem https://www.smashingmagazine.com/2018/01/understanding-using-rest-api/.
Przykładowych API do których możemy się łączyć jest mnóstwo. Nasa ma swoje, jakieś ministerstwa pogody mają swoje itp.
Na stronach https://public-apis.io/ i https://github.com/public-apis/public-apis znajdziesz listy dziesiątek darmowych API, ale dość często wystarczy poszukać frazy "Coś API".
Zanim przejdziesz dalej, spróbuj przyjrzeć się przykładowemu api: https://jsonplaceholder.typicode.com/. Jest to strona, która umożliwia wykonywanie fejkowych połączeń. Fejkowych, bo dane możesz ściągnąć, coś dodać, chociaż tak naprawdę nie będzie to zapisane na ich serwerze.
Gdy przewiniesz stronę w dół, zobaczysz adresy na które będziesz mógł wykonywać połączenia. Widzisz adres /posts? Podobnie do powyższych bohaterów. Gdy będziesz chciał pobrać wszystkie posty wykonasz zapytanie na https://jsonplaceholder.typicode.com/posts. Gdy będziesz chciał pobrać konkretny post, wykonasz zapytanie na https://jsonplaceholder.typicode.com/posts/id. Gdy będziesz chciał edytować treść danego posta, wyślesz PUT na adres https://jsonplaceholder.typicode.com/posts/id.
Możesz to sprawdzić wklejając dane adresy bezpośrednio w przeglądarkę. Możesz też wykorzystać opisywanego na dole PostMana.
XML
Wysyłając i pobierając dane, bardzo często będziemy chcieli przekazywać wiele danych na raz. Moglibyśmy to kodować pod postacią jakiegoś zaszyfrowanego tekstu, natomiast nie musimy tego robić.
Ajax - Asynchronous JavaScript and XML - widzisz tą końcówkę? Oznacza ona, że nasze dynamiczne połączenia będą operować głównie na danych w formacie XML.
Faktycznie - gdy powstawał Ajax, głównym formatem przesyłanych danych był XML. Format ten bardzo przypomina nasz HTML:
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<description>A former architect battles corporate zombies</description>
</book>
</catalog>
Pobieranie takich danych przypomina spacerowanie po drzewie dom:
function loadDoc() {
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = e => {
if (xhr.readyState === 4 && xhr.status === 200) {
showData(xhr);
}
};
xhr.open("GET", "books.xml", true);
xhr.send();
}
function showData(text) {
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(text.response, "text/xml");
const books = xmlDoc.querySelectorAll("book");
books.forEach(book => {
const title = book.querySelector("title").firstChild.nodeValue;
const author = book.querySelector("author").firstChild.nodeValue;
const genre = book.querySelector("genre").firstChild.nodeValue;
const price = Number(book.querySelector("price").firstChild.nodeValue);
const description = book.querySelector("description").firstChild.nodeValue;
console.log(`
tytuł: ${title},
autor: ${author},
rodzaj: ${genre},
cena: ${price},
opis: ${description}
`);
});
}
loadDoc();
JSON
XML sprawdza się w takiej komunikacji całkiem dobrze, ale można i lepiej. Dość szybko jako alternatywa dla tego formatu został wymyślony JSON - format, który bardzo uprościł prace na przesyłanych danych.
Format JSON do złudzenia przypomina klasyczne obiekty w JavaScript:
{
"catalog" : [
{
"id" : "bg101",
"author" : "Gambardella, Matthew",
"title" : "XML Developer's Guide",
"genre" : "Computer",
"price" : 44.95,
"description" : "An in-depth look at creating applications with XML."
},
{
"id" : "bg102",
"author" : "Ralls, Kim",
"title" : "Midnight Rain",
"genre" : "Fantasy",
"price" : 5.95,
"description" : "A former architect battles corporate zombies"
}
]
}
Jest jednak kilka różnic, które go odróżnia od obiektów:
- To format dla danych - dlatego nie może zawierać funkcji
- Nazwy kluczy i wartości tekstowe piszemy w cudzysłowach (żadnych apostrofów, żadnych backticków)
- Żadnych komentarzy - format JSON służy tylko do przechowywania danych
- Żadnego brakującego i nadmiarowego przecinka. Wszystko ma być tip-top jak w wojsku.
- Teksty piszemy w jednej linii - nawet te na wiele linii. Musimy tutaj zastosować jakieś znaki nowej linii (np.
\n), które potem odpowiednio skonwertujemy.
Praca na takich danych do złudzenia przypomina pracę na klasycznych obiektach. Wynika to z faktu, że po konwersji dane te stają się zwykłym obiektem:
const json = "...";
const data = JSON.parse(json);
const el = data[0];
const id = el.id;
const author = el.author;
const title = el.title;
const genre = el.genre;
const price = el.price;
const description = el.description;
//lub za pomocą destrukturyzacji w ES6
const {id, author, title, genre, price, description} = data[0];
Format JSON najczęściej zapisuje się w plikach z rozszerzeniem .json.
W dzisiejszych czasach możesz go spotkać na każdym kroku. Mamy go w każdym projekcie Node (package.json), ale i praktycznie każda nowa aplikacja korzysta z takich plików. Chociażby Visual Studio Code gdzie wszelkie ustawienia trzymane są właśnie w tym formacie (ciut zmodyfikowanym, bo ma komentarze), ale i podobne aplikacje korzystają właśnie z tego formatu.
My głównie będziemy go wykorzystywać w komunikacji z wszelakimi serwerami.
Praca z JSON
Do pracy z tym formatem w JavaScript bardzo pomocny okaże się obiekt JSON. Udostępnia on nam 2 metody: stringify() i parse().
Pierwsza z nich zamienia dany obiekt na tekstowy zapis w formacie JSON. Druga z nich zamienia zakodowany wcześniej tekst na obiekt JavaScript:
const ob = {
name : "Piotr",
surname : "Nowak"
}
const obStr = JSON.stringify(ob);
console.log(obStr); //"{"name":"Piotr","surname":"Nowak"}"
console.log( JSON.parse(obStr) ); //nasz wcześniejszy obiekt
Do czego to może się przydać? W przypadku Ajax będziemy go wykorzystywać do wysyłania danych na serwer w formacie JSON.
const ob = {
name : "Piotr",
surname : "Nowak",
car : {
brand : "Fiat",
color: "red"
}
}
fetch("...", {
headers: {
contentType : "application/json",
},
body : JSON.stringify(ob)
});
Są też inne zastosowania tego obiektu. Możemy go użyć do zapisywania obiektu w dataset czy chociażby kopiowaniu obiektów.
Czym się łączyć
W czystym JavaScript do obsługi dynamicznych połączeń (XHR) możemy skorzystać z 2 rzeczy: obiektu XMLHttpRequest oraz fetch.
Ten pierwszy istnieje nierozłączenie od początku istnienia Ajax. Mnogość opcji, ale i nieco kodu, który musimy napisać przy realnych projektach sprawiają, że sporo osób uważa je za nie do końca wygodne rozwiązanie.
Ten drugi w wielu sytuacjach będzie prostszy w użyciu, a to dzięki domyślnej obsłudze obietnic, a i kilku nowym interfejsom takim jak Headers, Response, Request. Trzeba mieć jednak na uwadze, że nie każda przeglądarka go obsłuży.
Możemy też skorzystać z gotowych bibliotek. Najczęściej wybieranymi są Ajax w jQuery oraz Axios. Ich powszechne zastosowanie wynika z faktu, że jeszcze bardziej ułatwiają pracę z połączeniami (np. biorąc na siebie obsługę błędów), ale też zapewniają działanie na starszych przeglądarkach.
//pobieranie danych za pomocą XMLHttpRequest
const xhr = new XMLHttpRequest();
xhr.onload = function() {
if (xhr.status === 200) {
const data = JSON.parse(xhr.response);
console.log(data);
}
}
xhr.open("GET", "https://jsonplaceholder.typicode.com/posts", true);
xhr.send();
//pobieranie danych za pomocą fetch - wersja uproszczona
fetch("https://jsonplaceholder.typicode.com/users")
.then(res => res.json())
.then(res => {
console.log(res);
});
//jquery
$.ajax({
url : "https://jsonplaceholder.typicode.com/users"
}).done(res => {
console.log(res);
})
//lub
$.get("https://jsonplaceholder.typicode.com/users").done(res => {
console.log(res);
})
//axios
axios.get("https://jsonplaceholder.typicode.com/users")
.then(res => {
console.log(res);
})
Pobieranie danych i CORS
Żeby pobrać i wysyłać dane, musimy mieć nasz skrypt i miejsce do którego będziemy się łączyć.
Wyobraź sobie teraz sytuację, że właśnie robisz prostą stronę internetową. Stworzyłeś katalog, a w nim plik html ze skryptem. Do tego samego katalogu wrzucasz dodatkowy plik json, który chcesz dynamicznie pobrać. Odpalasz stronę 2x klikając na nią, patrzysz w konsolę debuggera, a tam zamiast pobranych danych pojawia się długi czerwony błąd. Niestety pobieranie danych - nawet z tego samego katalogu się nie uda.
Ale czemu właściwie się nie uda?
Rozchodzi się o zabezpieczenia typu CORS - Cross-Origin Resource Sharing.
Klasyczne połączenia, które na co dzień robimy za pomocą naszej przeglądarki (czyli wpisujemy w adresie przeglądarki dany adres) możemy wykonywać w dowolne miejsca w internecie. Najwyżej dostaniemy 404 i cofniemy się do poprzedniej strony.
Sytuacja zmienia się w przypadku dynamicznych połączeń wykonywanych za pomocą Javascript. Ze względów bezpieczeństwa takie połączenia domyślnie możemy wykonywać tylko w obrębie własnej domeny, lub do serwerów, które dadzą ci znać, że możesz od nich pobierać dane.
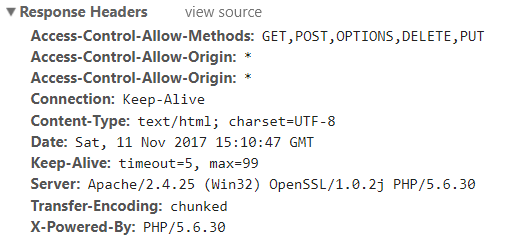
A jak dadzą znać? Wysyłając odpowiedni nagłówek (response headers):
Access-Control-Allow-Origin "*"
Access-Control-Allow-Methods: "GET,POST,OPTIONS,DELETE,PUT"
Pierwszy nagłówek wskazuje na domeny, które mogą wykonywać dynamiczne połączenia na ten serwer. Gwiazdka oznacza dowolną domenę. Drugi nagłówek określa możliwe typy połączeń.
Poniżej przykładowa odpowiedź z jednego z publicznych api:

W bardzo wielu przypadkach gdy się połączysz z jakimś serwisem by pobrać dane, w twojej konsoli pojawi się wspomniany złowieszczy komunikat:

Oznacza on, że nie możesz się dynamicznie łączyć z tym serwerem. Jeżeli wiesz dobrze, że adres jest poprawny i powinieneś móc się połączyć, od razu męcz administratorów danego serwera, bo prawdopodobnie dali ciała i nie wysyłają ci odpowiednich nagłówków...
Istnieją też nieco inne - mniej oficjalne sposoby ominięcia tego zabezpiecznia. Można na przykład spróbować skorzystać ze strony https://cors-anywhere.herokuapp.com/, która pozwala omijać CORS. Wystarczy do jej adresu dodać adres serwera, który ma problem z CORS:
const apiUrl = "http://my-bad-server.com/movies";
const corsAnywhereUrl = "https://cors-anywhere.herokuapp.com/";
const url = corsAnywhereUrl + apiUrl;
fetch(url).then(...)
Dla niektórych przeglądarek istnieją też dodatki, które pozwalają wyłączyć te zabezpieczenia.
Dla Chrome to np. ten a dla Firefoxa np. ten.
Dla reszty przeglądarek łatwo coś odnaleźć szukając "nazwa przeglądarki disable cors plugin".
Czy polecam to podejście? Chyba nie. Prawdopodobieństwo tego, że użytkownik, który wejdzie na twoją stronę będzie miał zainstalowany podobny dodatek jest równy wygranej 6 w Totka. Osobiście wolę metodę pierwszą - męczenie administratorów. Nawet tak dla zasady - co będą fikać do nas frontendowców 😁...
Innym rozwiązaniem CORS jest stworzenie pośredniego "serwera agregującego". Problem CORS dotyczy tylko przeglądarek. Strona backendowa spokojnie może takie połączenia wykonywać. Wystarczy stworzyć mini serwer (np. w Express, Php, Pythonie itp.), który będzie łączył się z danym serwerem, pobierał stamtąd dane, a my będziemy się łączyć z naszym.
Tak czy siak, przy pracy z Ajaxem nie unikniemy jednej rzeczy - pracy z własnym serwerem. Pomówimy sobie o nim w kolejnym rozdziale.
Dodatkowy ciekawy artykuł na ten temat znajdziesz tutaj.
Dodatkowy film na te tematy znajdziesz pod adresem https://www.youtube.com/watch?v=4KHiSt0oLJ0
Postman
Zanim przejdziemy do właściwej pracy ostatnie mini narzędzie, które może nam się przydać.
Często zamiast ręcznie pisać skrypt do testowania połączeń, lepiej skorzystać z jakiegoś programu, który umożliwi nam szybkie przetestowanie takiego połączenia. Po co pisać cokolwiek i zastanawiać się czy nasza składnia jest prawidłowa, skoro można zrobić test naciskając pojedynczy przycisk.
Jednym z bardziej znanych programów służących do testowania requestów jest Postman. Od jakiegoś czasu istnieje też wersja online, do której trzeba się tylko zarejestrować.

Jego podstawowe użycie jest tak proste, że w zasadzie po odpaleniu wystarczy zacząć testować dane połączenia.
Alternatywą dla Postmana jest użycie waszych edytorów. Webstorm ma swoje własne narzędzia do testowania połączeń, a i dla VSC coś się znajdzie (chociaż nie testowałem).

A jeżeli powyższe rozwiązania nam nie pasują, zawsze znajdzie się stosowna alternatywa.
Trening czyni mistrza
Jeżeli chcesz sobie potrenować zdobytą wiedzę, zadania znajdują się w repozytorium pod adresem: https://github.com/kartofelek007/zadania